Utilisation de l'IA pour l'analyse des sinistres avec des données non structurées
Sommaire : Cet article décrit un projet pilote visant à transformer les données d'indemnisation non structurées, comme les notes médicales et les rapports d'experts, en variables actuarielles exploitables grâce aux grands modèles de langage (LLM). La méthodologie repose sur une architecture à deux étapes qui extrait d'abord des informations précises de documents isolés avant de les synthétiser à l'échelle du dossier complet. En utilisant des données synthétiques pour l'entraînement et une validation par des experts cliniques, l'étude démontre une précision d'extraction élevée. L'intégration de ces nouvelles variables dans les méthodes de provisionnement traditionnelles a permis de réduire l'erreur d'estimation des réserves de 6,5 % à 4,0 %. Ce cadre offre ainsi aux actuaires une solution systématique et reproductible pour valoriser des informations narratives jusqu'alors sous-exploitées. Finalement, l'approche favorise une meilleure gestion des risques et une tarification plus précise tout en respectant les exigences réglementaires de transparence.
L'analyse actuarielle traditionnelle s'appuie historiquement sur des données structurées, numériques et catégorielles. Cependant, une part prépondérante de la valeur prédictive reste confinée dans des formats non structurés - notes cliniques, rapports d'experts, transcriptions d'appels - souvent inaccessibles aux modèles stochastiques sans un retraitement manuel lourd. L'étude « Leveraging LLMs for Unstructured Claims Data Analysis » par Robert D. Lieberthal et al. (2025) met en lumière ce fossé critique entre la richesse narrative des dossiers de sinistres et les exigences de rigueur des modèles quantitatifs. Ce document détaille comment les Large Language Models (LLM) transforment ce paradigme en convertissant des récits complexes en variables exploitables pour le provisionnement et la tarification.
1. Le défi des données non structurées en gestion des sinistres
Le traitement manuel des dossiers de sinistres présente des limites structurelles majeures pour l'actuaire : une latence élevée, des coûts opérationnels prohibitifs et une variabilité interévaluateur qui nuit à la qualité des données. Les méthodes du traitement automatique du langage naturel (TALN) traditionnelles, basées sur des règles rigides ou des approches par mots-clés, échouent à capturer les nuances sémantiques, les abréviations médicales complexes et le contexte clinique évolutif.
Contrairement à ces approches, les LLM offrent une compréhension contextuelle avancée, permettant de normaliser des descriptions qualitatives (ex: la distinction entre un traitement conservateur et une rééducation complexe) en données structurées. Cette capacité est fondamentale pour réduire les biais de sélection et enrichir les triangles de développement avec des variables jusqu'alors inexploitées.
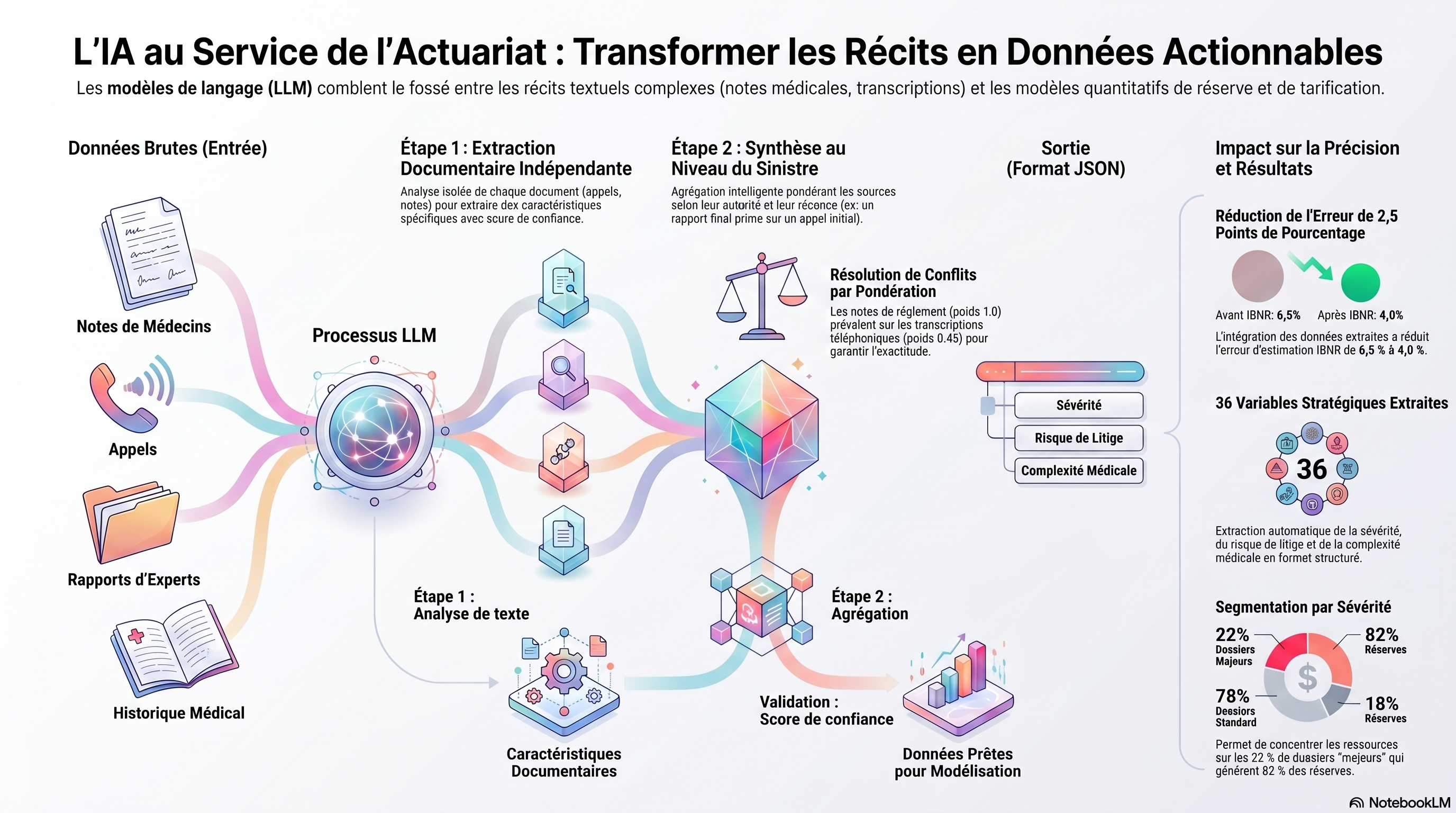
2. Architecture du système : Une approche en deux étapes
Le prototype utilise une architecture modulaire conçue pour isoler l'évidence textuelle avant sa synthèse finale, évitant ainsi les phénomènes d'interférence d'informations (« information bleeding ») :
- Étape 1 (Extraction au niveau du document) : Chaque pièce (notes cliniques, transcriptions, rapports) est analysée en isolation. Le système extrait 62 caractéristiques spécifiques par document, garantissant que l'analyse d'un document n'influence pas l'interprétation d'un autre.
- Étape 2 (Synthèse au niveau du sinistre) : Cette phase agrège les données de l'étape 1 pour générer 36 variables actuarielles consolidées. Pour résoudre les contradictions, le système applique une pondération d'autorité hiérarchisée :
- Notes de règlement (poids 1.0)
- Lettres médicales (poids 0.95)
- Notes initiales de l'expert en sinistres (poids 0.70)
- Transcriptions téléphoniques (poids 0.45)
Cette étape intègre également un mécanisme de dépréciation temporelle, accordant une importance accrue aux documents les plus récents pour refléter l'état le plus actuel du sinistre.
3. Taxonomie des variables actuarielles extraites
Le système génère des variables de « Stage 2 » destinées à l'intégration directe dans les modèles de provisionnement. Sur les 36 variables identifiées, 14 constituent le socle de l'analyse de sévérité et de risque.
Catégorie de Variable | Exemples de Variables (Valeurs typiques) |
Sévérité et Complexité | Sévérité du sinistre (Mineure, Majeure, Catastrophique), Complexité médicale (Simple, Haute) |
Trajectoire Clinique | Type de traitement (Conservateur, Chirurgical, Rééducation complexe), Statut MMI (Atteint/Non atteint) |
Risque et Litige | Probabilité de litige (Faible, Moyenne, Haute), Niveau de risque (Faible à Extrême) |
Indicateurs de Coût | Catégorie de coût ultime (<25K, 25K-150K, >150K), Prédiction du coût ultime (Valeur USD) |
Gestion Opérationnelle | Complexité de gestion (Routine, High-touch), Probabilité de règlement |
4. Validation et performance : De la théorie à la précision des réserves
La rigueur de la méthode a été validée par un protocole d'expertise clinique sur un échantillon de 20 sinistres, confirmant la robustesse du modèle :
- Métriques de précision : Les scores de validation ont excédé 4/5 sur l'échelle de Likert. L'étude rapporte un score Kappa pondéré de 0,53, indiquant une fiabilité inter-juges modérée à forte, cohérente avec les standards de l'industrie pour des jugements qualitatifs complexes.
- Calibration de la confiance : Un résultat clé pour la gouvernance des risques montre que les variables avec un score de confiance >0,85 présentent une corrélation de plus de 95 % avec les évaluations des experts humains.
- Impact sur les provisions pour sinistres à payer (PSAP) : Testée sur un jeu de données synthétique de 420 sinistres, l'intégration des classifications de sévérité LLM dans un modèle Chain Ladder a réduit l'erreur d'estimation des IBNR (Sinistres survenus mais non déclarés) de 6,5 % à 4,0 %, soit une amélioration de 2,5 points de pourcentage.
5. Intégration opérationnelle et considérations de coûts
La mise en œuvre s'appuie sur un pipeline Python modulaire composé de quatre scripts, optimisant le « Workflow 2 » (analyse de sinistres réels) via le Text Aggregator et le Claims Analyzer :
- Efficience : Le temps de traitement par sinistre est de 5 à 10 minutes, pour un coût oscillant entre 0,50 $ et 5,00 $, rendant la solution scalable pour des portefeuilles de masse.
- Interopérabilité : Les sorties utilisent des schémas JSON standardisés, permettant une injection directe dans les entrepôts de données actuariels et une utilisation immédiate sous R ou Python pour l'ajustement des triangles de développement.
6. Limites critiques et impératifs de conformité
L'ingénierie des risques impose de reconnaître les limites inhérentes à l'outil :
- Qualité du signal : Les erreurs d'OCR sur des documents scannés de mauvaise qualité peuvent altérer l'extraction de données critiques.
- Conformité réglementaire : La désidentification rigoureuse des données est un préalable non négociable pour respecter les cadres HIPAA et RGPD.
- Surveillance du modèle : Une validation continue est requise pour détecter les dérives liées à l'évolution de la terminologie médicale ou des pratiques de codification des experts.
Conclusion
L'émergence de « l'actuaire augmenté » par l'IA ne substitue pas le jugement professionnel, mais le dote d'une capacité de stratification sans précédent. Le LLM doit être appréhendé comme un outil de transformation des données narratives en indicateurs quantitatifs, permettant de traiter l'hétérogénéité des portefeuilles avec une précision chirurgicale. En libérant la valeur piégée dans le texte, cette technologie assure une estimation plus fidèle des engagements futurs et une gestion optimisée des provisions techniques.