La propriété d'équilibre et le partage des risques en assurance
Source : Wüthrich, M.V. (2026). The Balance Property: The Constrained Case, with a View on Risk Sharing.
Sommaire : Cet article examine la « propriété d'équilibre » dans les modèles statistiques utilisés pour la tarification en assurance, selon laquelle le montant total des primes estimées doit correspondre au montant total des sinistres observés dans l'échantillon. Il compare trois méthodes permettant de rétablir cette propriété lorsque les modèles GLM à liens non canoniques ne la respectent pas. L'auteur montre que l'estimation sous contrainte (SC) offre de meilleures performances asymptotiques que les approches de quasi-vraisemblance (QMLE) et de post-traitement simple (SPP). L'étude établit également un lien entre cette propriété d'équilibre et les mécanismes de partage des risques ex post.
1. Introduction et contexte théorique
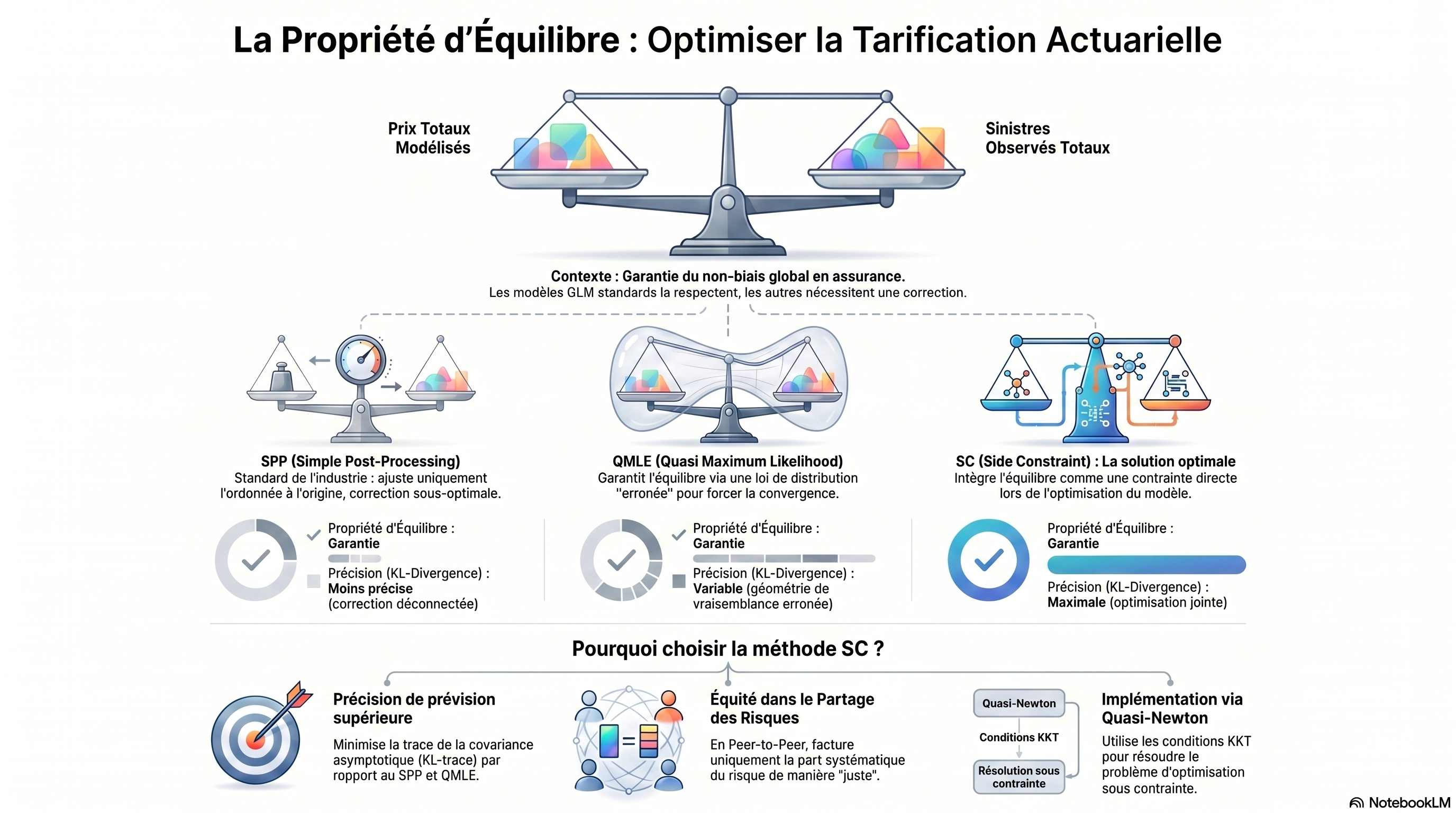
En tarification actuarielle, la propriété d'équilibre (balance property) est une exigence de premier plan. Elle garantit que la somme des primes pures allouées au sein d'un portefeuille est égale à la charge totale des sinistres observés sur l'échantillon d'apprentissage. Mathématiquement, cette propriété s'interprète comme une condition de non-biais global in-sample.
Dans le cadre des modèles linéaires généralisés (GLM), cette propriété est nativement satisfaite lorsque l'on utilise un lien canonique. En revanche, dès que l'actuaire opte pour un lien non canonique (souvent pour des raisons métier ou de structure de prix), cette égalité n'est plus assurée. Techniquement, cela provient du fait que les équations de score du maximum de vraisemblance (MLE) ne sont plus alignées : la fonction de lien g n'est plus l'inverse de la dérivée de la fonction de cumulant κ, ce qui empêche la simplification des termes de la fonction de score Ψ(β) permettant d'isoler l'égalité d'équilibre.
2. Définition mathématique de la propriété d'équilibre
Soit un échantillon d'apprentissage 𝒟 = (Yi, Xi, Wi) n, i=1, où Yi est la réponse, Xi le vecteur de covariables de dimension q + 1, et Wi le poids d'exposition. La fonction de régression estimée μ̂ satisfait la propriété d'équilibre si :
∑ (i=1 à n) Wi μ̂(Xi) = ∑ (i=1 à n) Wi Yi
Cette condition assure que le niveau de prix global est correctement spécifié. Pour un gestionnaire de risques, l'absence de cette propriété introduit un biais systématique qui fausse l'appréciation de la rentabilité technique globale du portefeuille.
3. Analyse comparative des méthodes de rectification
Lorsque le lien choisi g n'est pas canonique, trois méthodes permettent de restaurer l'équilibre :
- Maximum de vraisemblance quasi-identifié (QMLE) : Cette approche consiste à substituer la distribution réelle par une distribution de la famille exponentielle de dispersion (EDF) "erronée", dont le lien canonique coïnciderait avec le lien g choisi. Si elle rétablit l'équilibre, elle le fait au mépris de la structure de variance réelle des données.
- Post-traitement simple (SPP) : Il s'agit du standard industriel actuel. On ajuste d'abord le modèle par MLE standard, puis on décale uniquement l'ordonnée à l'origine (intercept) par un facteur γ pour forcer l'égalité globale. C'est une procédure découplée en deux étapes.
- Optimisation sous contrainte (SC) : Cette méthode ajuste le MLE en intégrant la propriété d'équilibre comme une contrainte de Karush-Kuhn-Tucker (KKT).
L'approche SC est mathématiquement supérieure. Contrairement au SPP, elle optimise l'ensemble du vecteur de paramètres β simultanément. Contrairement au QMLE, elle opère dans la "bonne" géométrie de vraisemblance en respectant la structure de variance réelle des données, évitant ainsi les biais d'estimation liés à une mauvaise spécification de la distribution.
4. Démonstration de la supériorité de l'approche SC
La performance d'un estimateur β̃ est ici mesurée par la trace de sa matrice de covariance asymptotique Σ̃ pondérée par la matrice d'information H. Nous définissons d'abord les matrices de structure (sous l'hypothèse de variance correcte σ2(X) = V(μ(X;β+))) :
J = E [ (W/φ) (1/V(μ)) (1/g'(μ))² XX⊤ ] I = E [ (W/φ) (σ2(X)/V(μ)²) (1/g'(μ))² XX⊤ ] H = E [ (W/φ) (1/σ2(X)) (1/g'(μ))² XX⊤ ]
Le Théorème 5.1 (Wüthrich, 2026) établit la hiérarchie suivante :
q + 1 ≤ trace(H Σsc) ≤ min { trace(H ΣQMLE), trace(H ΣSPP) }
Interprétation pour la gestion des risques : Le terme q + 1 représente la variance de l'estimateur MLE non contraint (le plus efficace, mais biaisé globalement). L'inégalité démontre que l'approche SC est la méthode de rectification la plus précise (variance minimale) parmi toutes celles garantissant l'équilibre global. Elle minimise la divergence de Kullback-Leibler (KL) moyenne, offrant ainsi la meilleure capacité prédictive sous contrainte de non-biais.
5. Lien avec le partage des risques ex-post (Peer-to-Peer)
La propriété d'équilibre est le fondement des mécanismes de partage des risques dans les pools Peer-to-Peer (P2P). Dans ces structures, la perte totale S = ∑ Wi Yi est allouée ex-post entre les participants. La règle de partage par espérance conditionnelle (CMRS) définit la contribution de chacun.
L'optimisation sous contrainte (SC) apporte une dimension de "justice actuarielle" fondamentale :
- Régularisation vs Solution triviale : Sans contrainte structurelle, la solution de partage serait Ki = Wi Yi, ce qui correspond à une auto-assurance pure et annule l'intérêt de la mutualisation. L'approche SC utilise la classe de modèles de régression pour séparer la composante systématique μ(Xi) de l'aléa idiosyncrasique εi.
- Le "Gold Standard" du lien canonique : Si l'actuaire utilise un lien canonique, le partage des risques est intrinsèquement "juste" car il facture exactement le prix des effets systématiques estimés.
- Optimisation de l'information : L'approche SC permet de ne facturer que la part systématique ajustée, garantissant que les participants partagent mutuellement la part aléatoire du risque tout en étant tarifés sur leurs caractéristiques individuelles propres.
6. Considérations pratiques et limites
Sur le plan de la mise en œuvre, la méthode SC est plus exigeante qu'un GLM standard :
- Calcul du Hessien : L'algorithme d'optimisation doit traiter les équations KKT en (β, λ). Cela nécessite le calcul du Hessien de la fonction de Lagrange par rapport aux paramètres et au multiplicateur de Lagrange.
- Algorithme : Il est recommandé d'utiliser des méthodes quasi-Newton, initialisées sur les coefficients du MLE non contraint pour garantir une convergence efficace.
- Structure de variance : La supériorité théorique de l'approche SC repose sur une spécification correcte de la variance. Si celle-ci est inconnue, l'actuaire peut recourir à un schéma d'estimation itératif tel que proposé par Delong-Wüthrich (2025) pour estimer conjointement la moyenne et la variance.
- Concept Drift : Bien que l'équilibre soit garanti in-sample, la validité out-of-sample reste sujette aux dérives de concept. L'actuaire doit donc surveiller la stabilité temporelle des paramètres.